You are viewing the v1 docs for LangChain, which is currently under active development. Learn more. Overview
Memory is a system that remembers information about previous interactions.
For AI agents, memory is crucial because it lets them remember previous interactions, learn from feedback,
and adapt to user preferences. As agents tackle more complex tasks with numerous user interactions,
this capability becomes essential for both efficiency and user satisfaction.
Short term memory lets your application remember previous interactions within a single thread or conversation.
A thread organizes multiple interactions in a session, similar to the way email groups messages in a single conversation.
Usage
To add short-term memory (thread-level persistence) to an agent, you need to specify a checkpointer when creating
an agent.
LangChain’s agent manages short-term memory as a part of your agent’s state.
By storing these in the graph’s state, the agent can access the full context for a given conversation while maintaining separation between different threads.State is persisted to a database (or memory) using a checkpointer so the thread can be resumed at any time.
Short-term memory updates when the agent is invoked or a step (like a tool call) is completed, and the state is read at the start of each step.
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
"openai:gpt-5",
[get_user_info],
checkpointer=InMemorySaver(),
)
agent.invoke(
{"messages": [{"role": "user", "content": "Hi! My name is Bob."}]},
{"configurable": {"thread_id": "1"}},
)
In production
In production, use a checkpointer backed by a database:
from langchain.agents import create_agent
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
agent = create_agent(
"openai:gpt-5",
[get_user_info],
checkpointer=checkpointer,
)
Customizing agent memory
By default, agents use AgentState to manage short term memory, specifically the conversation history via a messages key.
Users can subclass AgentState to add additional fields to the state.
This custom state can then be accessed via tools and dynamic prompt / model functions.
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
class CustomAgentState(AgentState):
user_id: str
agent = create_agent(
"openai:gpt-5",
[get_user_info],
state_schema=CustomAgentState,
checkpointer=InMemorySaver(),
)
Common Patterns
With short-term memory enabled, long conversations can exceed the LLM’s context window. Common solutions are:
- Trim messages: Remove first or last N messages (before calling LLM)
- Delete messages from LangGraph state permanently
- Summarize messages: Summarize earlier messages in the history and replace them with a summary
- Custom strategies (e.g., message filtering, etc.)
This allows the agent to keep track of the conversation without exceeding the LLM’s context window.
Trim messages
Most LLMs have a maximum supported context window (denominated in tokens).
One way to decide when to truncate messages is to count the tokens in the message history
and truncate whenever it approaches that limit. If you’re using LangChain, you can use the
trim messages utility and specify the number of tokens to keep from the list, as well as the strategy
(e.g., keep the last maxTokens) to use for handling the boundary.
To trim message history in an agent, use @[pre_model_hook][create_agent] with the trim_messages function:
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
from langchain_core.messages import BaseMessage
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent
from langchain_core.runnables import RunnableConfig
def pre_model_hook(state) -> dict[str, list[BaseMessage]]:
"""
This function will be called prior to every llm call to prepare the messages for the llm.
"""
trimmed_messages = trim_messages(
state["messages"],
strategy="last",
token_counter=count_tokens_approximately,
max_tokens=384,
start_on="human",
end_on=("human", "tool"),
)
return {"llm_input_messages": trimmed_messages}
checkpointer = InMemorySaver()
agent = create_agent(
"openai:gpt-5-nano",
tools=[],
pre_model_hook=pre_model_hook,
checkpointer=checkpointer,
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
"""
================================== Ai Message ==================================
Your name is Bob. You told me that earlier.
If you’d like me to call you a nickname or use a different name, just say the word.
"""
Delete messages
You can delete messages from the graph state to manage the message history.
This is useful when you want to remove specific messages or clear the entire message history.
To delete messages from the graph state, you can use the RemoveMessage.
For RemoveMessage to work, you need to use a state key with add_messages reducer,.
The default AgentState provides this.
To remove specific messages:
from langchain_core.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# remove the earliest two messages
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def delete_messages(state):
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}
When deleting messages, make sure that the resulting message history is valid. Check the limitations of the LLM provider you’re using. For example:
- some providers expect message history to start with a
user message
- most providers require
assistant messages with tool calls to be followed by corresponding tool result messages.
from langchain_core.messages import RemoveMessage
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# remove the earliest two messages
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
agent = create_agent(
"openai:gpt-5-nano",
tools=[],
prompt="Please be concise and to the point.",
post_model_hook=delete_messages,
checkpointer=InMemorySaver(),
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
for event in agent.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values",
):
print([(message.type, message.content) for message in event["messages"]])
for event in agent.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values",
):
print([(message.type, message.content) for message in event["messages"]])
[('human', "hi! I'm bob")]
[('human', "hi! I'm bob"), ('ai', 'Hi Bob! Nice to meet you. How can I help you today? I can answer questions, brainstorm ideas, draft text, explain things, or help with code.')]
[('human', "hi! I'm bob"), ('ai', 'Hi Bob! Nice to meet you. How can I help you today? I can answer questions, brainstorm ideas, draft text, explain things, or help with code.'), ('human', "what's my name?")]
[('human', "hi! I'm bob"), ('ai', 'Hi Bob! Nice to meet you. How can I help you today? I can answer questions, brainstorm ideas, draft text, explain things, or help with code.'), ('human', "what's my name?"), ('ai', 'Your name is Bob. How can I help you today, Bob?')]
[('human', "what's my name?"), ('ai', 'Your name is Bob. How can I help you today, Bob?')]
Summarize messages
The problem with trimming or removing messages, as shown above, is that you may lose information from culling of the message queue.
Because of this, some applications benefit from a more sophisticated approach of summarizing the message history using a chat model.
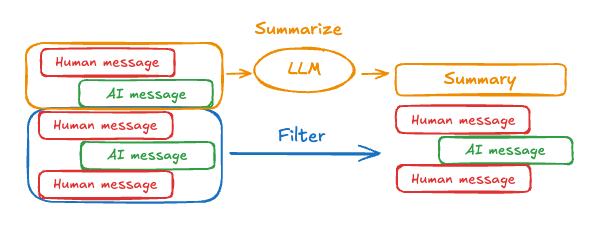 To summarize message history in an agent, use @[
To summarize message history in an agent, use @[pre_model_hook][create_agent] with a prebuilt SummarizationNode abstraction:
from langmem.short_term import SummarizationNode, RunningSummary
from langchain_core.messages.utils import count_tokens_approximately
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableConfig
model = ChatOpenAI(model="gpt-4o-mini")
summarization_node = SummarizationNode(
token_counter=count_tokens_approximately,
model=model,
max_tokens=384,
max_summary_tokens=128,
output_messages_key="llm_input_messages",
)
class State(AgentState):
# Added for the SummarizationNode to be able to keep track of the running summary information
context: dict[str, RunningSummary]
checkpointer = InMemorySaver()
agent = create_agent(
model=model,
tools=[],
pre_model_hook=summarization_node,
state_schema=State,
checkpointer=checkpointer,
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
print(final_response.keys())
final_response["messages"][-1].pretty_print()
print("\nSummary:", final_response["context"]["running_summary"].summary)
Access
You can access the short-term memory of an agent in a few different ways:
Access short term memory (state) in a tool by injecting the agent’s state into the tool signature with the InjectedState annotation.
This annotation hides the state from the tool signature (so the model doesn’t see it), but the tool can access it.
from typing import Annotated
from langchain.agents import create_agent, AgentState
from langchain.agents.tool_node import InjectedState
class CustomState(AgentState):
user_id: str
def get_user_info(
state: Annotated[CustomState, InjectedState]
) -> str:
"""Look up user info."""
user_id = state["user_id"]
return "User is John Smith" if user_id == "user_123" else "Unknown user"
agent = create_agent(
model="openai:gpt-5-nano",
tools=[get_user_info],
state_schema=CustomState,
)
result = agent.invoke({
"messages": "look up user information",
"user_id": "user_123"
})
print(result["messages"][-1].content)
#> User is John Smith.
from typing import Annotated
from langchain_core.tools import InjectedToolCallId
from langchain_core.runnables import RunnableConfig
from langchain_core.messages import ToolMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.tool_node import InjectedState
from langgraph.runtime import get_runtime
from langgraph.types import Command
from pydantic import BaseModel
class CustomState(AgentState):
user_name: str
class CustomContext(BaseModel):
user_id: str
def update_user_info(
tool_call_id: Annotated[str, InjectedToolCallId],
) -> Command:
"""Look up and update user info."""
runtime = get_runtime(CustomContext)
user_id = runtime.context.user_id
name = "John Smith" if user_id == "user_123" else "Unknown user"
return Command(update={
"user_name": name,
# update the message history
"messages": [
ToolMessage(
"Successfully looked up user information",
tool_call_id=tool_call_id
)
]
})
def greet(
state: Annotated[CustomState, InjectedState]
) -> str:
"""Use this to greet the user once you found their info."""
user_name = state["user_name"]
return f"Hello {user_name}!"
agent = create_agent(
model="openai:gpt-5-nano",
tools=[update_user_info, greet],
state_schema=CustomState,
context_schema=CustomContext,
)
agent.invoke(
{"messages": [{"role": "user", "content": "greet the user"}]},
context=CustomContext(user_id="user_123"),
)
Prompt
Access short term memory (state) in a dynamic prompt function by injecting the agent’s state into the prompt function signature.
from langchain_core.messages import AnyMessage
from langchain.agents import create_agent, AgentState
from langgraph.runtime import get_runtime
from typing import TypedDict
class CustomContext(TypedDict):
user_name: str
def get_weather(city: str) -> str:
"""Get the weather in a city."""
return f"The weather in {city} is always sunny!"
def prompt(state: AgentState) -> list[AnyMessage]:
user_name = get_runtime(CustomContext).context["user_name"]
system_msg = f"You are a helpful assistant. Address the user as {user_name}."
return [{"role": "system", "content": system_msg}] + state["messages"]
agent = create_agent(
model="openai:gpt-5-nano",
tools=[get_weather],
prompt=prompt,
context_schema=CustomContext,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
context=CustomContext(user_name="John Smith"),
)
for msg in result["messages"]:
msg.pretty_print()
================================ Human Message =================================
What is the weather in SF?
================================== Ai Message ==================================
Tool Calls:
get_weather (call_WFQlOGn4b2yoJrv7cih342FG)
Call ID: call_WFQlOGn4b2yoJrv7cih342FG
Args:
city: San Francisco
================================= Tool Message =================================
Name: get_weather
The weather in San Francisco is always sunny!
================================== Ai Message ==================================
Hi John Smith, the weather in San Francisco is always sunny!
Pre Model Hook
Access short term memory (state) in a pre model hook by injecting the agent’s state into the hook signature.
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
from langchain_core.messages import BaseMessage
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
def pre_model_hook(state: AgentState) -> dict[str, list[BaseMessage]]:
"""
This function will be called prior to every llm call to prepare the messages for the llm.
"""
trimmed_messages = trim_messages(
state["messages"],
strategy="last",
token_counter=count_tokens_approximately,
max_tokens=384,
start_on="human",
end_on=("human", "tool"),
)
return {"llm_input_messages": trimmed_messages}
agent = create_agent(
model="openai:gpt-5-nano",
tools=[],
pre_model_hook=pre_model_hook,
checkpointer=InMemorySaver(),
)
result = agent.invoke({"messages": "hi, my name is bob"}, {"configurable": {"thread_id": "1"}})
print(result["messages"][-1].content)
Post Model Hook
Access short term memory (state) in a post model hook by injecting the agent’s state into the hook signature.
from langchain.agents import create_agent, AgentState
STOP_WORDS = ["password", "secret"]
def validate_response(state: AgentState) -> dict[str, list[BaseMessage]]:
"""Confirm the response doesn't have any content that is in the stop words list."""
last_message = state["messages"][-1]
if any(word in last_message.content for word in STOP_WORDS):
return {"messages": [RemoveMessage(id=last_message.id)]}
return {}
agent = create_agent(
model="openai:gpt-5-nano",
tools=[],
post_model_hook=validate_response,
checkpointer=InMemorySaver(),
)

