

- Derived from token counts and model prices
- Directly specified as part of the run data
Send token counts
For LangSmith to accurately derive costs for an LLM run, you need to provide token counts:- If you are using the LangSmith Python or TS/JS SDK with OpenAI or Anthropic models, the built-in wrappers will automatically send up token counts, model provider and model name data to LangSmith.
- If you are using the LangSmith SDK’s with other model providers, you should carefully read through this guide.
- If you are using LangChain Python or TS/JS, token counts, model provider, and model name are automatically sent up to LangSmith for most chat model integrations. If there is a chat model integration that is missing token counts and for which the underlying API includes token counts in the model response, please open a GitHub issue in the LangChain repo.
tiktoken.
Specify model name
LangSmith reads the LLM model name from thels_model_name field in run metadata. The SDK built-in wrappers and any LangChain integrations will automatically handle specifying this metadata for you.
Set model prices
To compute costs from token counts and model names, we need to know the per-token prices for the model you’re using. LangSmith has a model pricing table for this. The table comes with pricing information for most OpenAI, Anthropic, and Gemini models. You can add prices for other models, or overwrite pricing for default models. You can specify prices for prompt (input) and completion (output) tokens. If needed you can provide a more detailed breakdown of prices. For example, some model providers have different pricing for multimodal or cached tokens.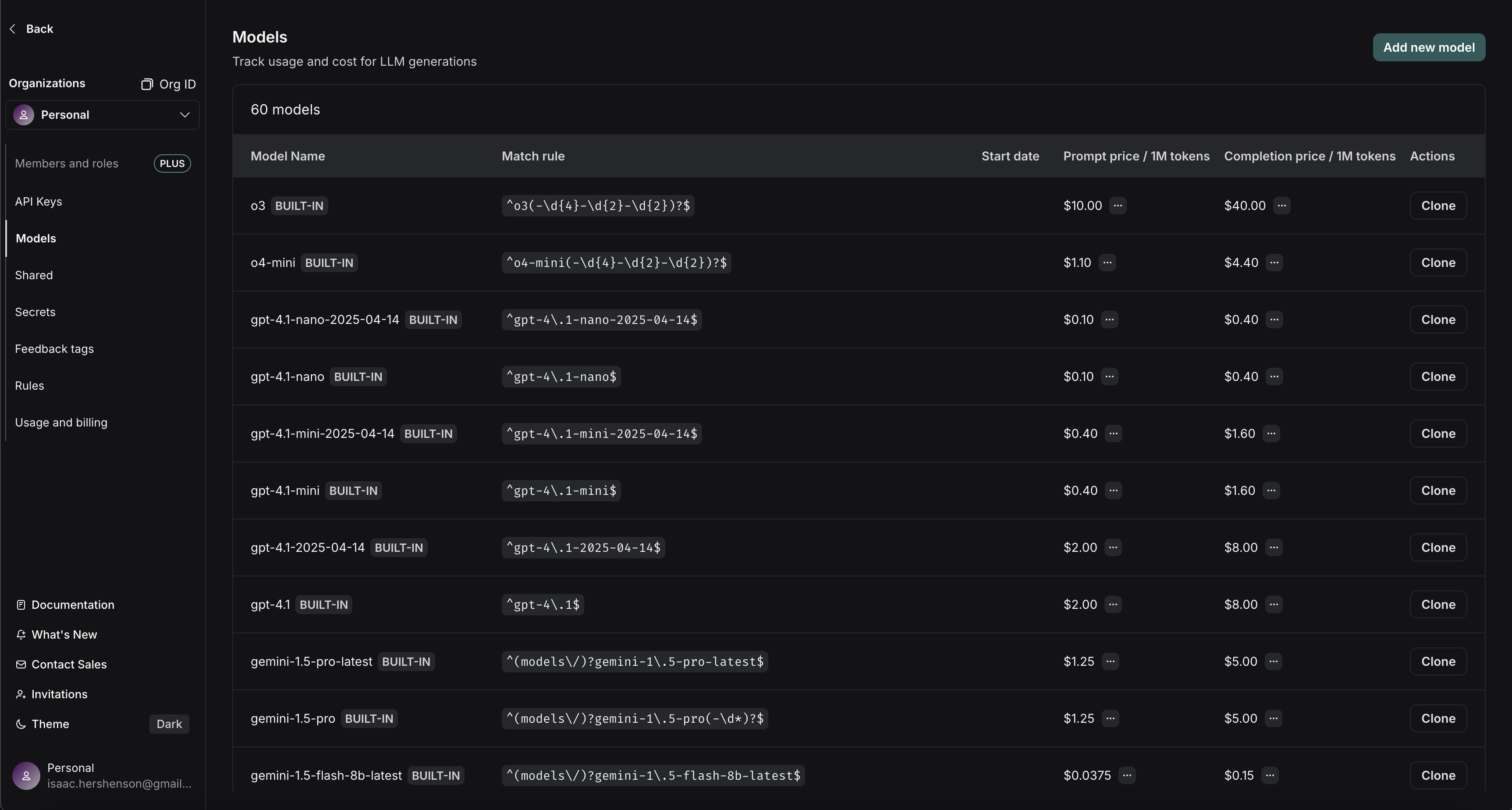
... next to the prompt/completion prices shows you the price breakdown by token type. You can see, for example, if audio and image prompt tokens have different prices versus default text prompt tokens.
To create a new entry in the model pricing map, click on the Add new model button in the top right corner.

- Model Name: The human-readable name of the model.
- Match Pattern: A regex pattern to match the model name. This is used to match the value for
ls_model_namein the run metadata. - Prompt (Input) Price: The cost per 1M input tokens for the model. This number is multiplied by the number of tokens in the prompt to calculate the prompt cost.
- Completion (Output) Price: The cost per 1M output tokens for the model. This number is multiplied by the number of tokens in the completion to calculate the completion cost.
- Prompt (Input) Price Breakdown (Optional): The breakdown of price for each different type of prompt token, e.g.
cache_read,video,audio, etc. - Completion (Output) Price Breakdown (Optional): The breakdown of price for each different type of completion token, e.g.
reasoning,image, etc. - Model Activation Date (Optional): The date from which the pricing is applicable. Only runs after this date will apply this model price.
- Provider (Optional): The provider of the model. If specified, this is matched against
ls_providerin the run metadata.
Please note that updates to the model pricing map are will not be reflected in the costs for traces already logged. We do not currently support backfilling model pricing changes.
Cost formula
The cost for a run is computed greedily from most-to-lease specific token type. Suppose we set a price of 1 per 1Mcache_read prompt tokens, and $3 per 1M completion tokens. If we uploaded the following usage metadata:
Send costs directly
If you are tracing an LLM call that returns token cost information, are tracing an API with a non-token based pricing scheme, or otherwise have accurate information around costs at runtime, you may instead populate ausage_metadata dict while tracing rather than relying on LangSmith’s built-in cost calculations.
See this guide to learn how to manually provide cost information for a run.